In this blog, I will try my best to simplify SaltStack, what is it, and why now?
VMware acquired SaltStack in October 2020 in the thick of the global pandemic.
This got me thinking, why did they acquire Salt?
Don’t they have enough automation tools?
Please watch the following video to get you started 👍
Thanks for watching the doodle!!!, let’s get into some details
End-to-End full stack automation is critical for a digital business
Doing point and disparate automation and using multiple tools is a thing of the past and doesn’t work for a digital business
Look at the role RPA (robotic process automation ) plays in today’s business – the more a company automates its process, the better the gains.
In the same lines, full-stack automation in IT is a critical need
This pandemic has made many of our customers realize this.
They can’t be talking to multiple teams (storage/compute/network/security) to get a VM with OS and DB installed and ready to go
Most customers have one tool to automate infrastructure and one to automate application deployment, and another to automate networking
VMware acquiring Salt is a brilliant move to bring some method to the chaos.
VMware vRealize Automation SaltStack Config brings the following value to the table
- Quickly and easily deploy and configure software across virtualized, hybrid, and public cloud environments
- Security and performance – hosts can now detect configurations drifts and auto remediate at scale
- Implement change immediately at a massive scale across the IT stack.
Following are some SaltStack use cases
- Configuration management
- Compliance and secure configuration enforcement
- Software deployment and updates
- Patching and orchestrated OS app maintenance
- Self-service infrastructure automation
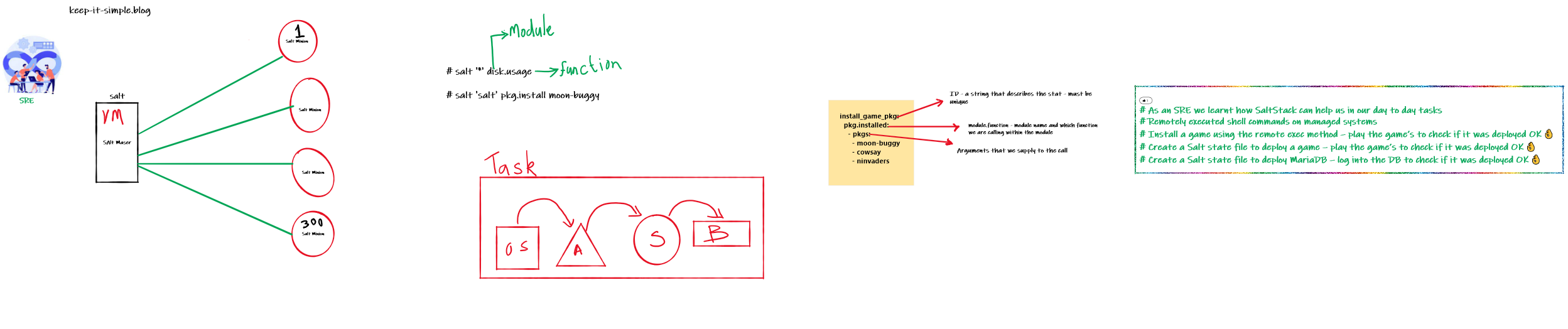
SaltStack Basic building blocks
- Salt is a simple client/server architecture
- The Salt Master and the Salt Minion
- Salt Master is a process that manages the salt infrastructure and dictates policies
- Salt Minions are the slave process installed on all managed hosts
- The job of a minion is to execute the instructions sent by the Salt Master, report job success, and provide data related to the underlying host
- Some Important SaltStack jargons , just FYI… We will learn as you progress
- Master – the central management system.
- Minions – a managed system
- States – What you use to determine the State of a machine, there are many states you can have – state of the a machine is the configuration a list of instructions on what Salt should to a minion
- Modules – Salt comes with built-in modules to install software, copy files, check services, and other tasks you want to automate
That’s all we need to know as of now…

Salt…. The essence of life
Let us learn Salt the practical way and do not get bogged down with technical content you don’t understand; Work with me on the story
Hands-on Task’s
- Download the OVF from – https://bit.ly/31iDF6I
- Import it into your VMWare workstation or player environment – instructions in the video
- VMware Workstation Player is free for personal, non-commercial use – download
- For credentials pls send me an email – roshan@keep-it-simple.blog
- Run some initial check to see Salt is installed and working
- Assume you are an SRE in your favorite company and perform the following automation activities
- Remotely execute shell commands on managed systems
- Install a game using the remote exec method – play the game’s to check if it was deployed 👌
- Create a Salt state file to deploy a game – play the game’s to check if it was deployed 👌
- Create a Salt state file to deploy MariaDB – log into the DB to check if it was deployed 👌
The CowSay's
_______________________________________
/ Keep IT simple- Humans respond to and \
| process visual data better than any |
\ other type of data /
---------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
Hence another video to help you with your exercise